Cross-cultural Studies > Transfer of results > EXEMPRAES Corpus
The Exemplary Empirical Research Articles in English and Spanish (EXEMPRAES) Corpus is an online interface developed by Laurence Anthony in collaboration with Ana I. Moreno. This tool was created to disseminate findings from cross-cultural studies conducted as part of the ENEIDA Project. This project was funded under the Spanish Ministry of Science and Innovation grant (Ref.: FFI2009-08336/FILO, 2010-mid 2014), with Ana I. Moreno as the Principal Investigator. The primary goals of the EXEMPRAES Corpus is to make cross-cultural research findings widely accessible in a user-friendly format to facilitate learning, teaching or further research.
Currently, the tool provides results from analyses of the rhetorical structure —down to the step level— of a small sample comprising 10 pairs of research article (RA) Discussion and/or Conclusion sections from the social sciences within the EXEMPRAES Corpora (Moreno, 2013). It uses Moreno’s (2021) annotations of these sections according to their communicative functions. The tool serves as a demonstration platform to test and showcase its features while awaiting the inclusion of more comprehensive data in the future.
Challenges of the Transfer of Cross-Cultural Results
The primary challenge was to develop a tool that could make our cross-cultural research findings accessible to Spanish academic learners and teachers, allowing them to:
- Compare how the same communicative function is expressed in similar contexts of empirical RAs in English and Spanish, without the texts being translations of each other.
- For example: compare how the step (e.g., Comparing with previous research and/or own hypotheses) within the same move (e.g., Commenting on key results or other features) is expressed and to what extent in the same RA section (e.g., Discussion and/or Conclusion), within the same broad knowledge area (e.g. Social Sciences) and discipline (e.g., Psychology) across English and Spanish.
- Compare how similar words or phrases in English and Spanish are used in similar contexts.
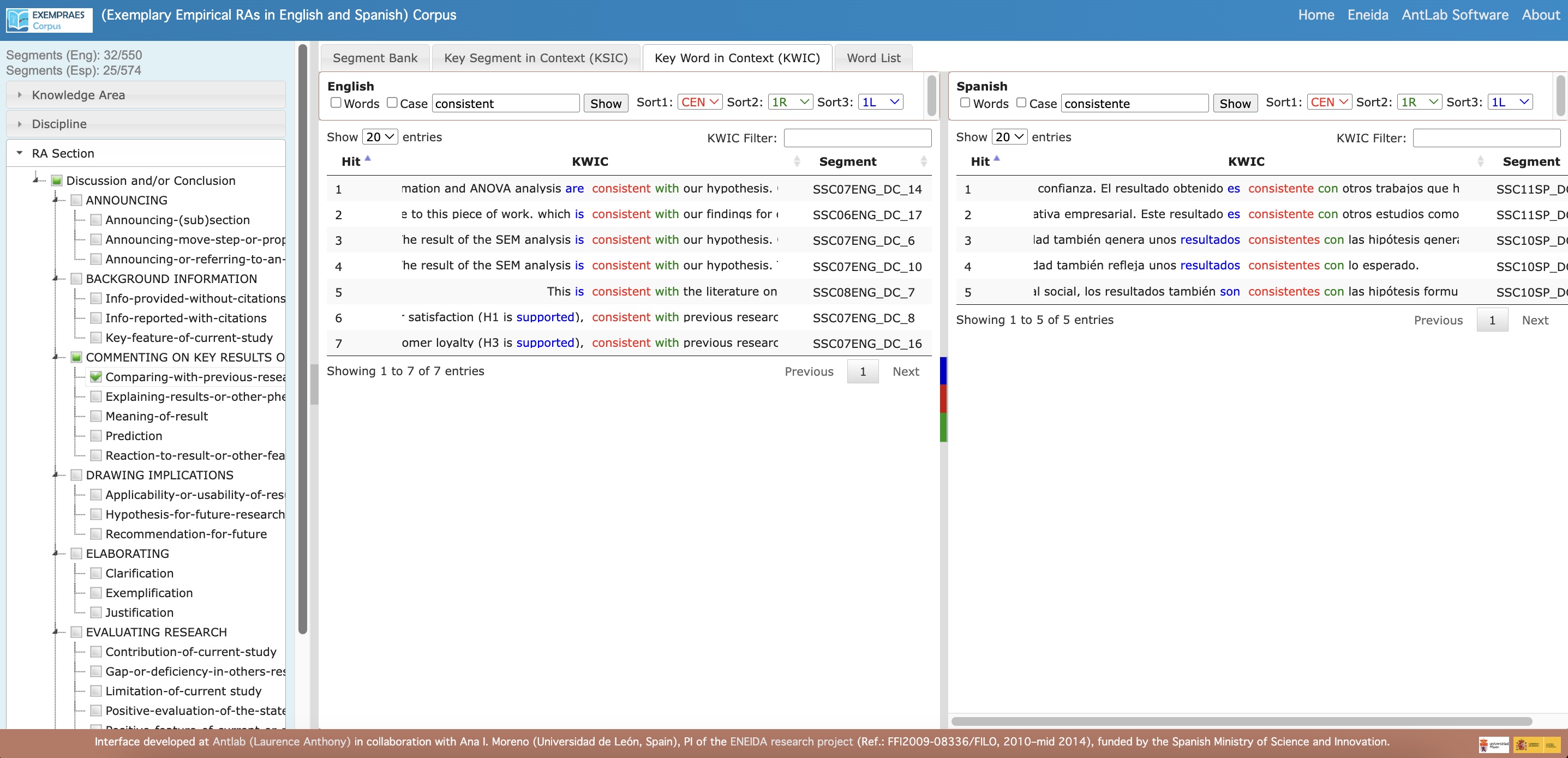
- For example: Investigate how the phrase “consistent with” in English and its equivalent, “consistente con,” in Spanish are used to express the same step (e.g., Comparing with previous studies) within the same move (e.g., Commenting on key results or other features) in the same RA section (e.g., Discussion and/or Conclusion section), within the same broad knowledge area (e.g. Social Sciences) and discipline (e.g., Psychology) in both languages.
These challenges and objectives directly inspired the development of the EXEMPRAES Corpus tool.
Innovations: The EXEMPRAES Corpus interface
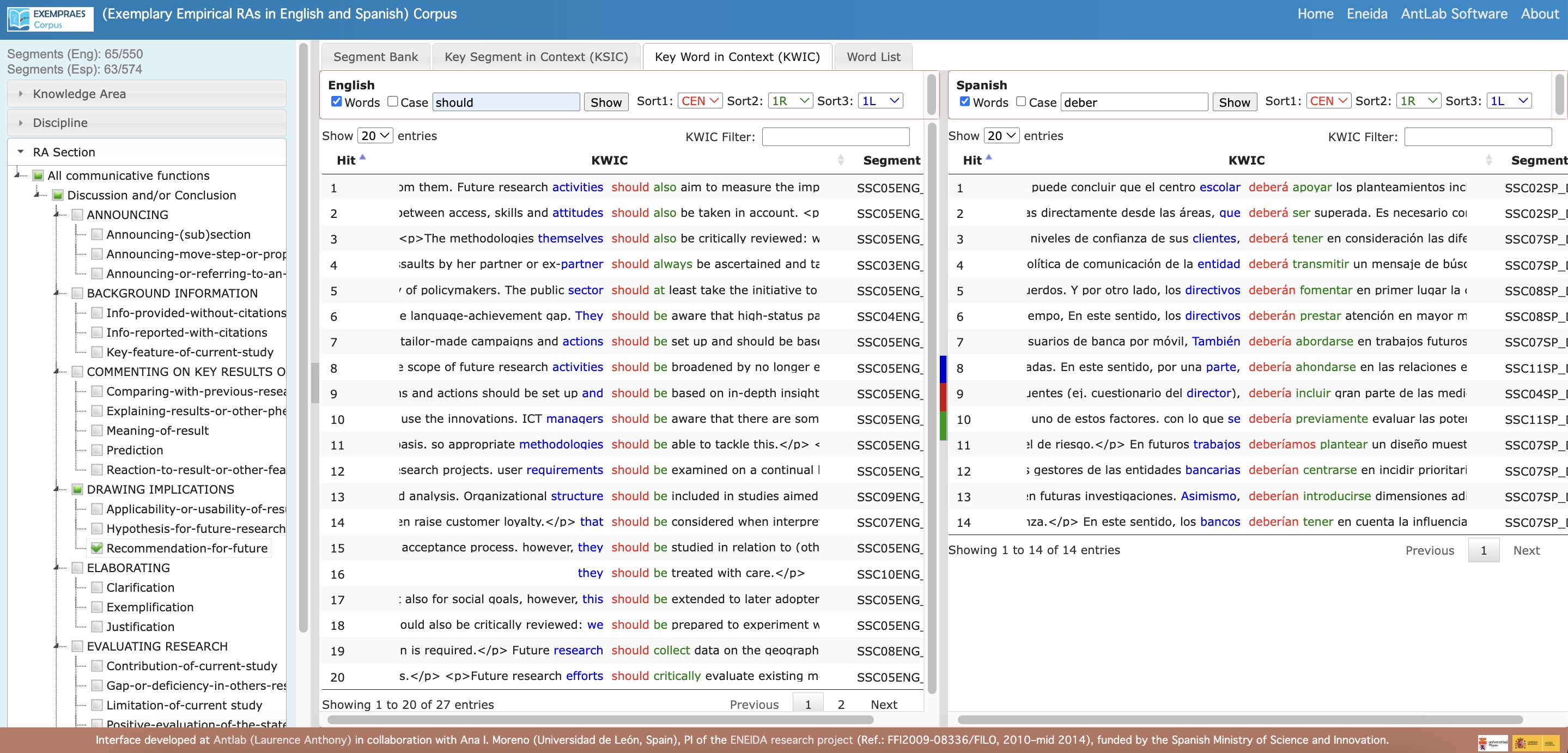
The EXEMPRAES Corpus features four main tools: Segment Bank, Key Segment in Context (KSIC), Key Word in Context (KWIC) and Word List.
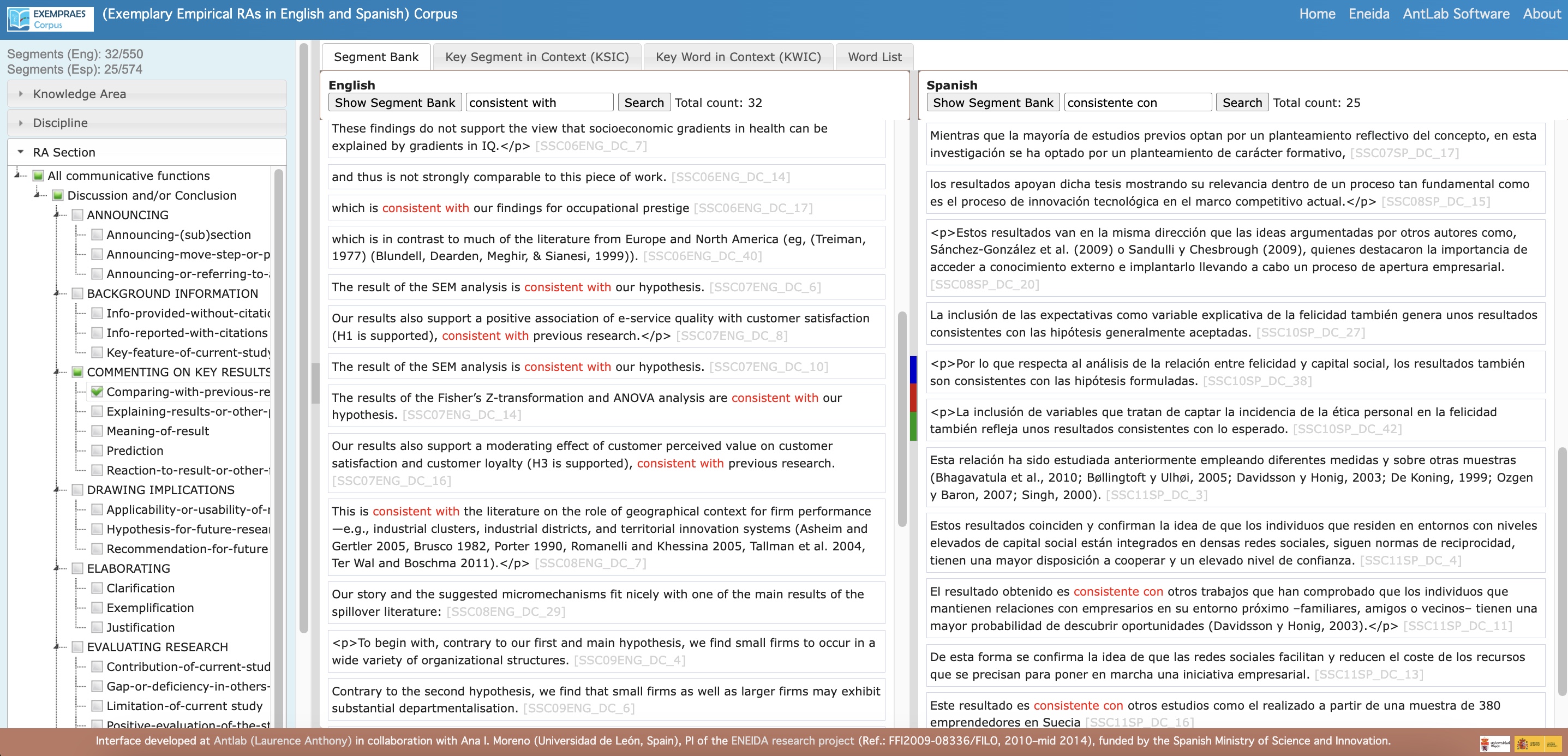
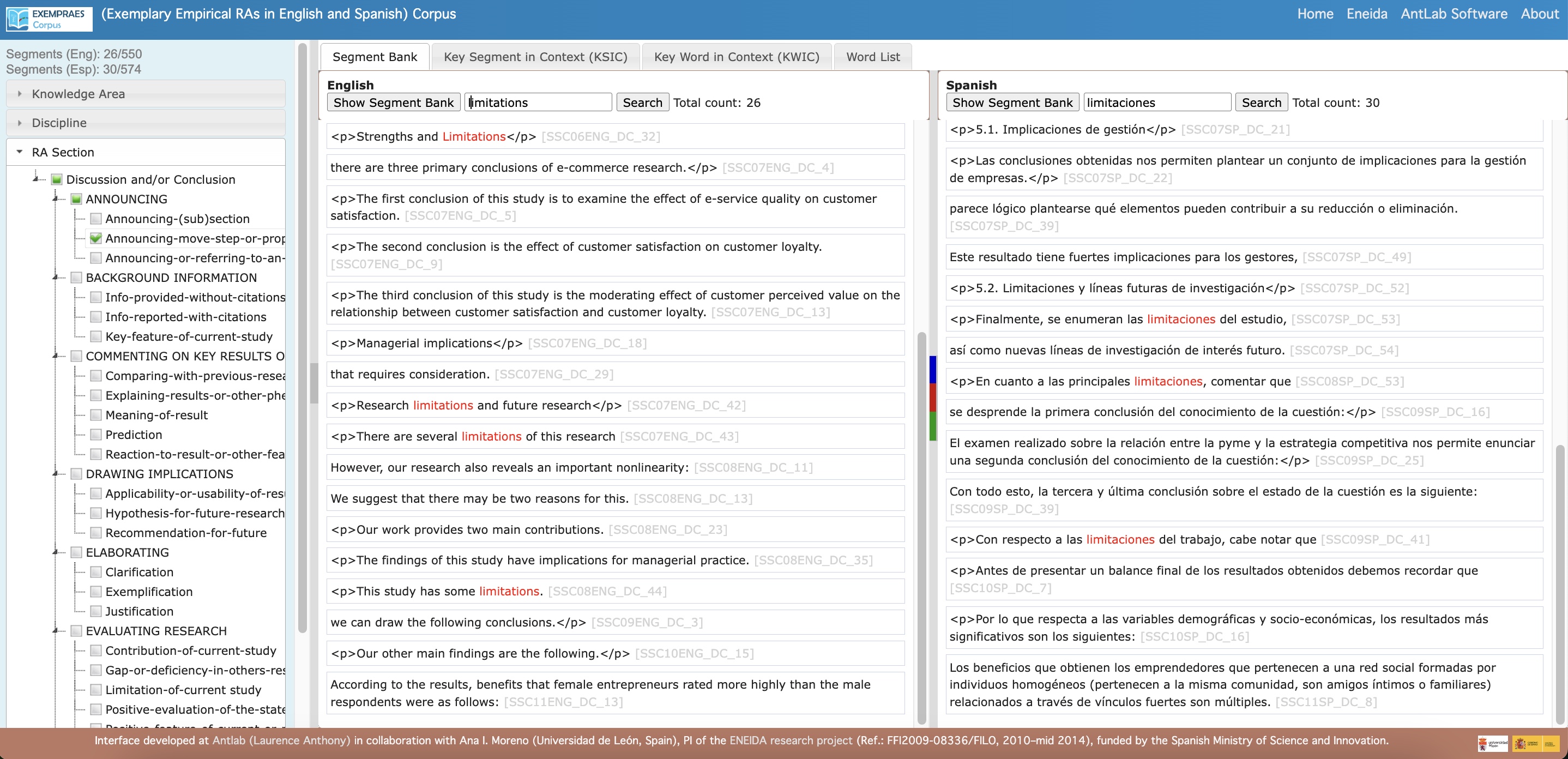
- Segment Bank: A standalone search tool that allows users to explore two datasets of annotated segments by language (English/Spanish), knowledge area, discipline, research article section, and general and/or specific communicative functions.
- Key Segment in Context (KSIC): When double-clicking on a segment in the Segment Bank or KWIC view to access a wider context, only sections of the source text are displayed, rather than the full text, in order to avoid copyright issues related to the original works.
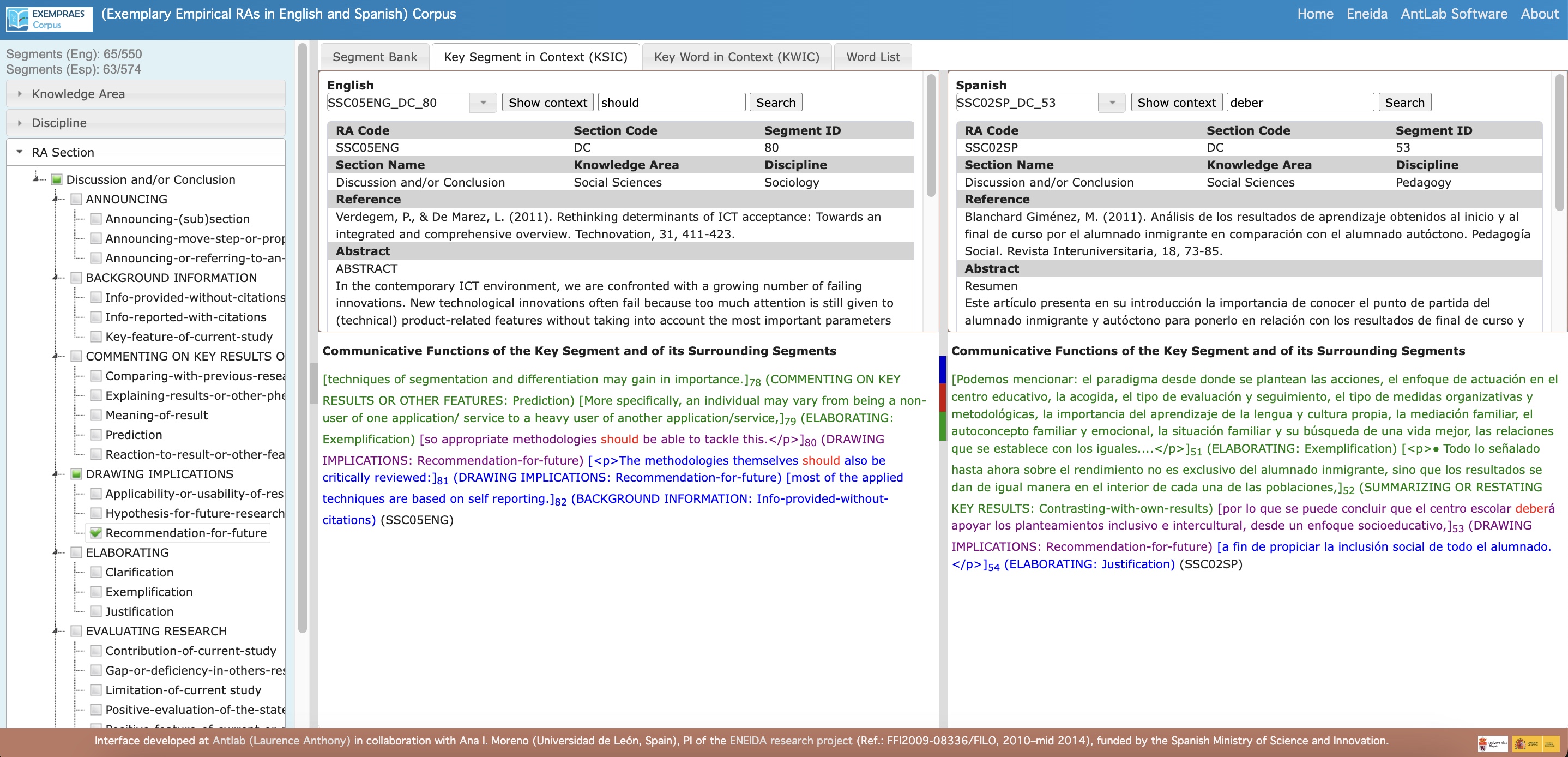
- Formatting: Displays text segments surrounding the KSIC with their correlative number and a specification of their general and specific communicative function, according to Moreno’s (2021) findings. Original formatting is not preserved for the same reason.
- Sources References: For every text segment displayed, the EXEMPRAES Corpus interface provides a reference to the original source.
- Sources Abstract: For every text segment displayed, the EXEMPRAES Corpus interface provides the abstract of the original source to offer a wider context.
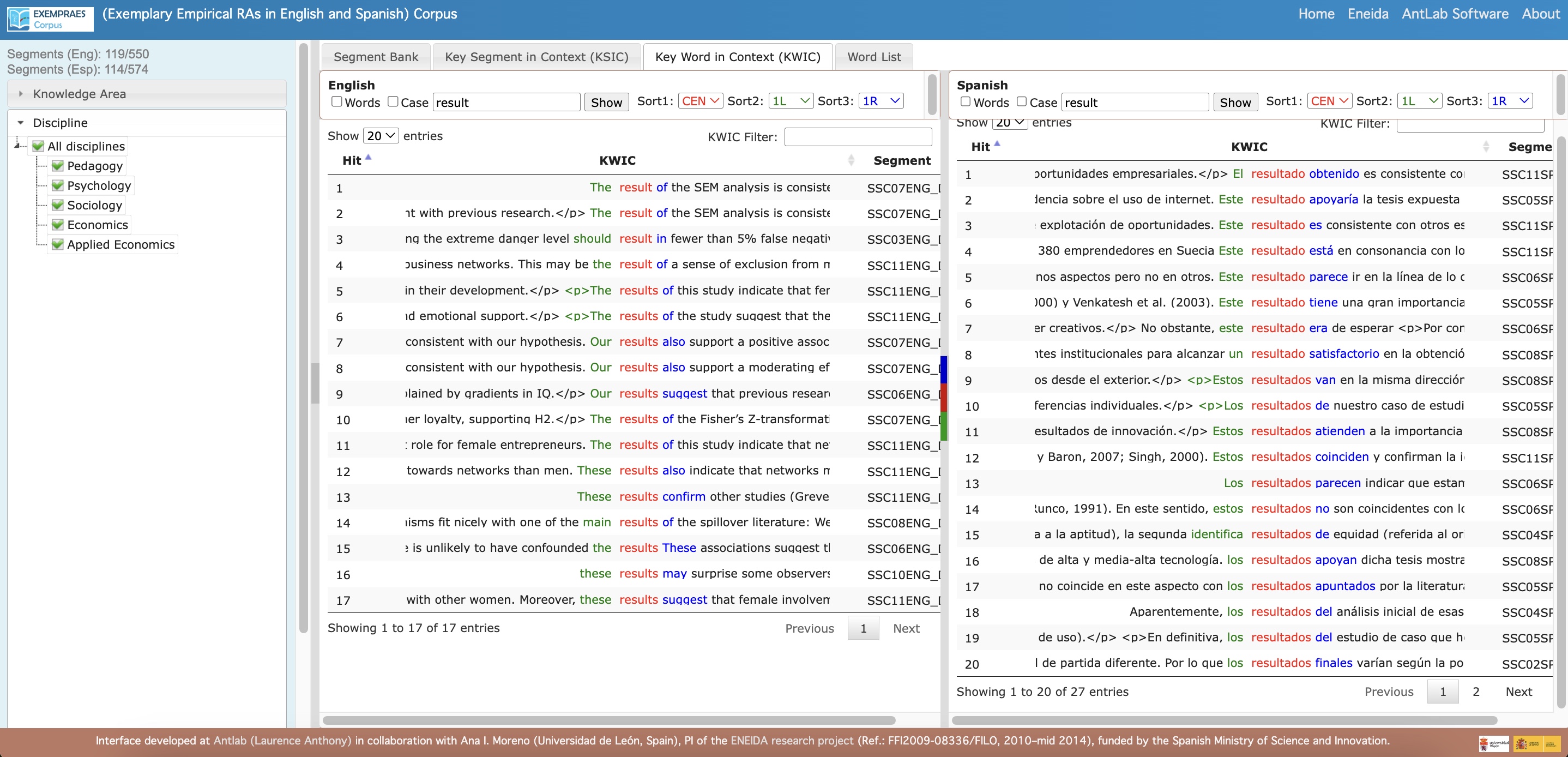
- Key Word in Context (KWIC): A concordancer view that displays two sets of search results side-by-side for easy comparison.
- Word List: Provides basic statistics of language features across two datasets.
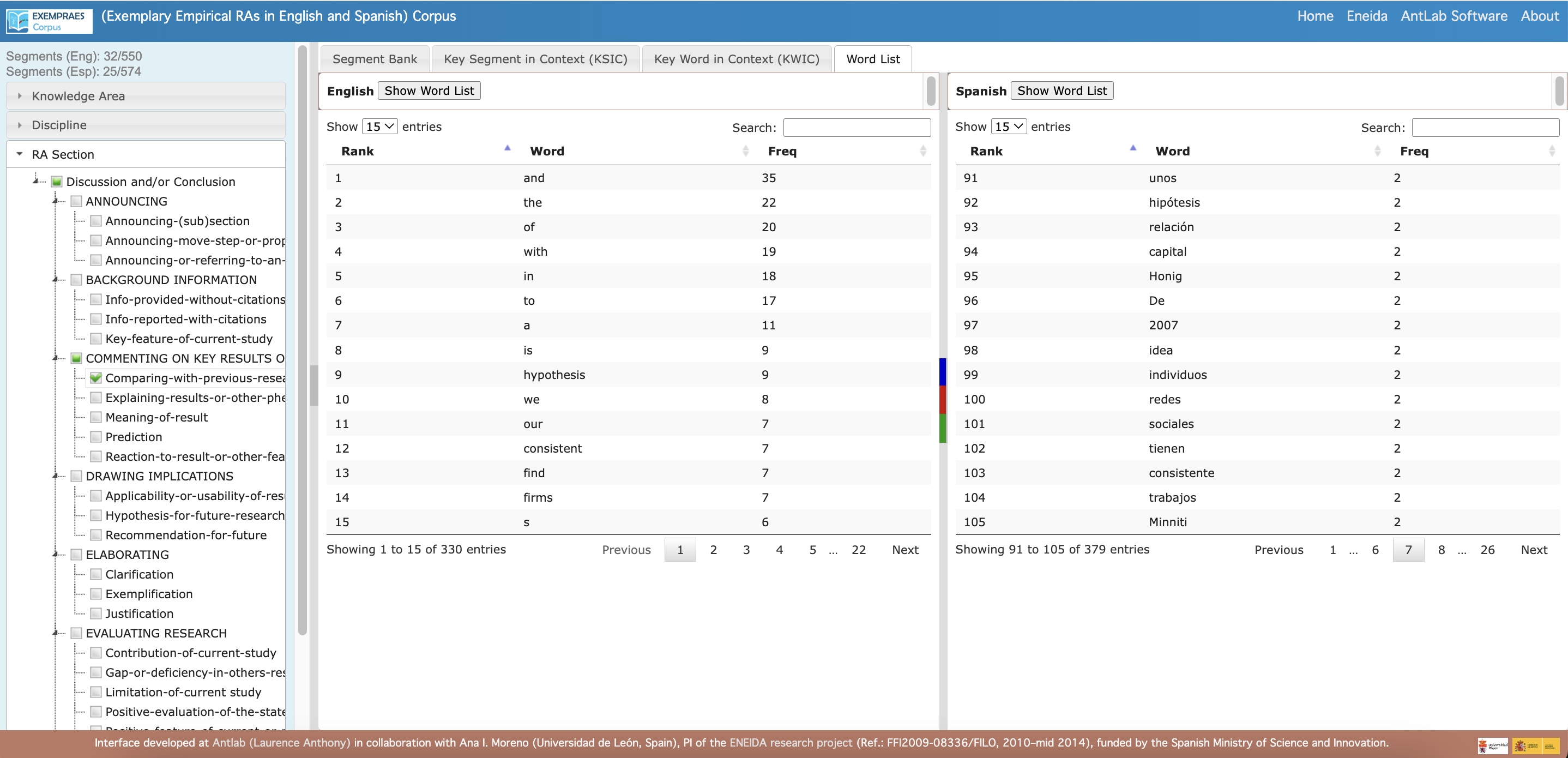
Highlights of The EXEMPRAES Corpus interface
The EXEMPRAES Corpus allows users to:
- Browse and filter the Corpora by
- Language (English/Spanish)
- Knowledge area and discipline
- Research article section
- Moves and (sub-)steps, as well as other general and specific functions (e.g., announcements, elaborations) across various research article sections.
- Access the Segment Bank: Obtain parallel lists of full segments that meet specified search conditions, with information about the source text and links to wider contexts.
- Search the Corpus for:
- Words or phrases in specific contexts (e.g., the word ‘may’ in the Explaining-results-or-other-phenomena-or-discussing-effects step within the ‘COMMENTING ON KEY RESULTS OR OTHER FEATURES’ move in the ‘Discussion and/or Conclusion’ section of RAs in Social Sciences).
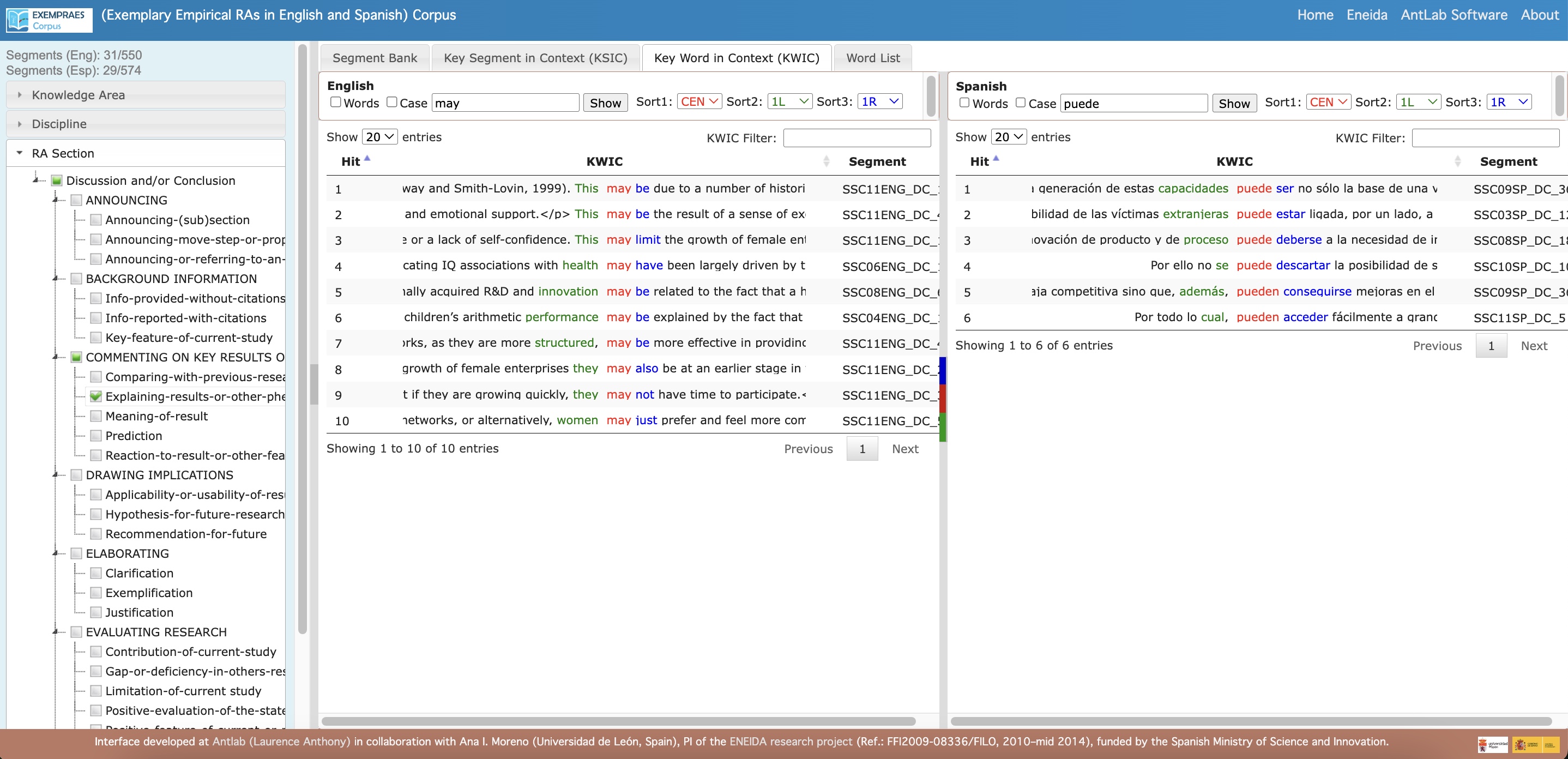
-
- Functions across the two languages for comparative analysis of similar segments (e.g., fragments stating a ‘limitation of the current study’ step in the ‘EVALUATING RESEARCH’ move of the ‘Discussion and/or Conclusion’ section in RAs from the Social Sciences to study how they are articulated, including notions, grammar, and phraseology).
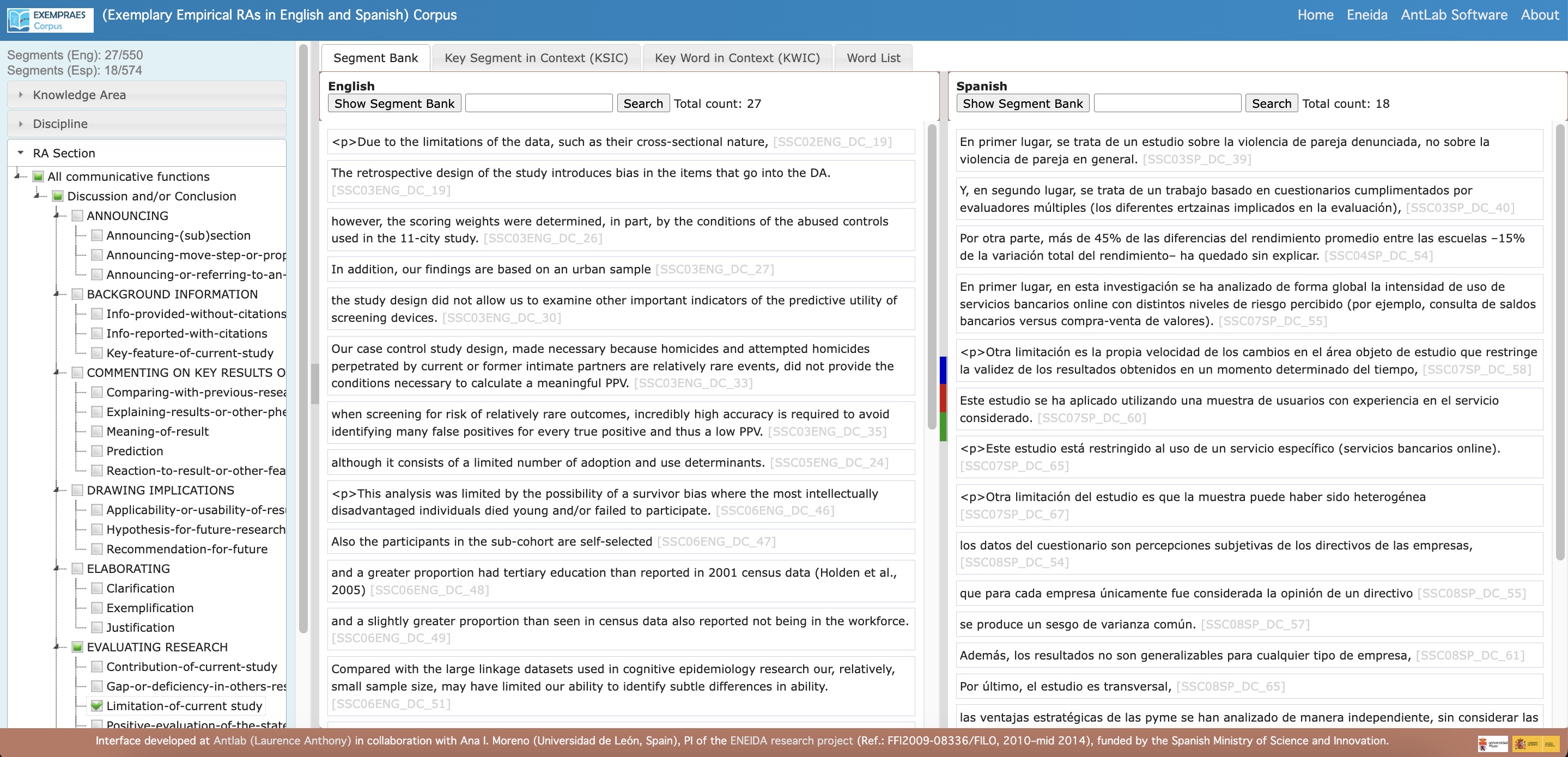
- Explore Current Data: Currently, the interface contains results from a small sample of comparable pairs of RA Discussion and/or Closing sections in Social Sciences disciplines, annotated using Moreno’s (2021) codebook.
- View Parallel Concordance Lines: Access concordance lines around searched words or phrases with:
- Information about the source text
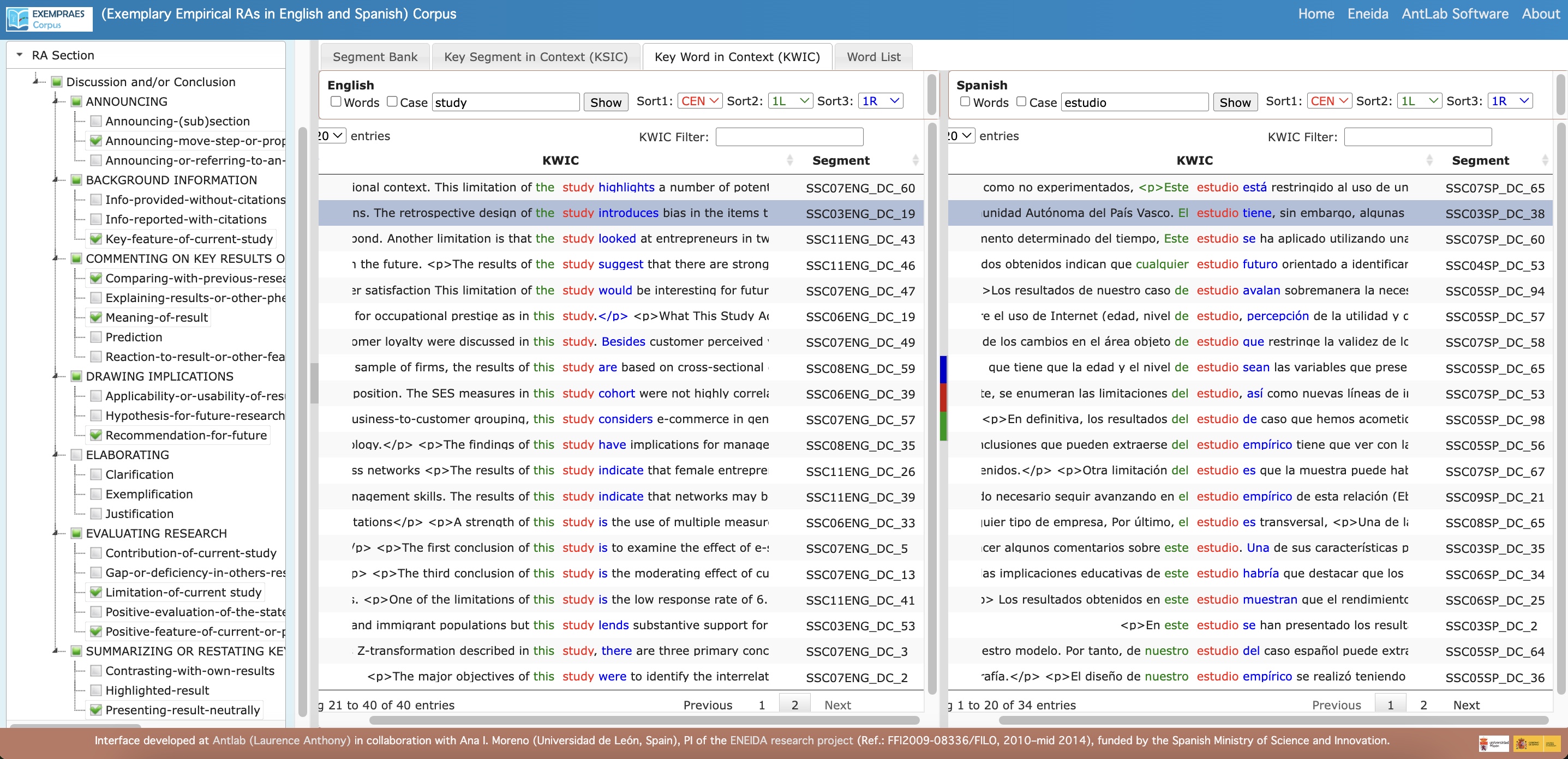
-
- Links to wider contexts
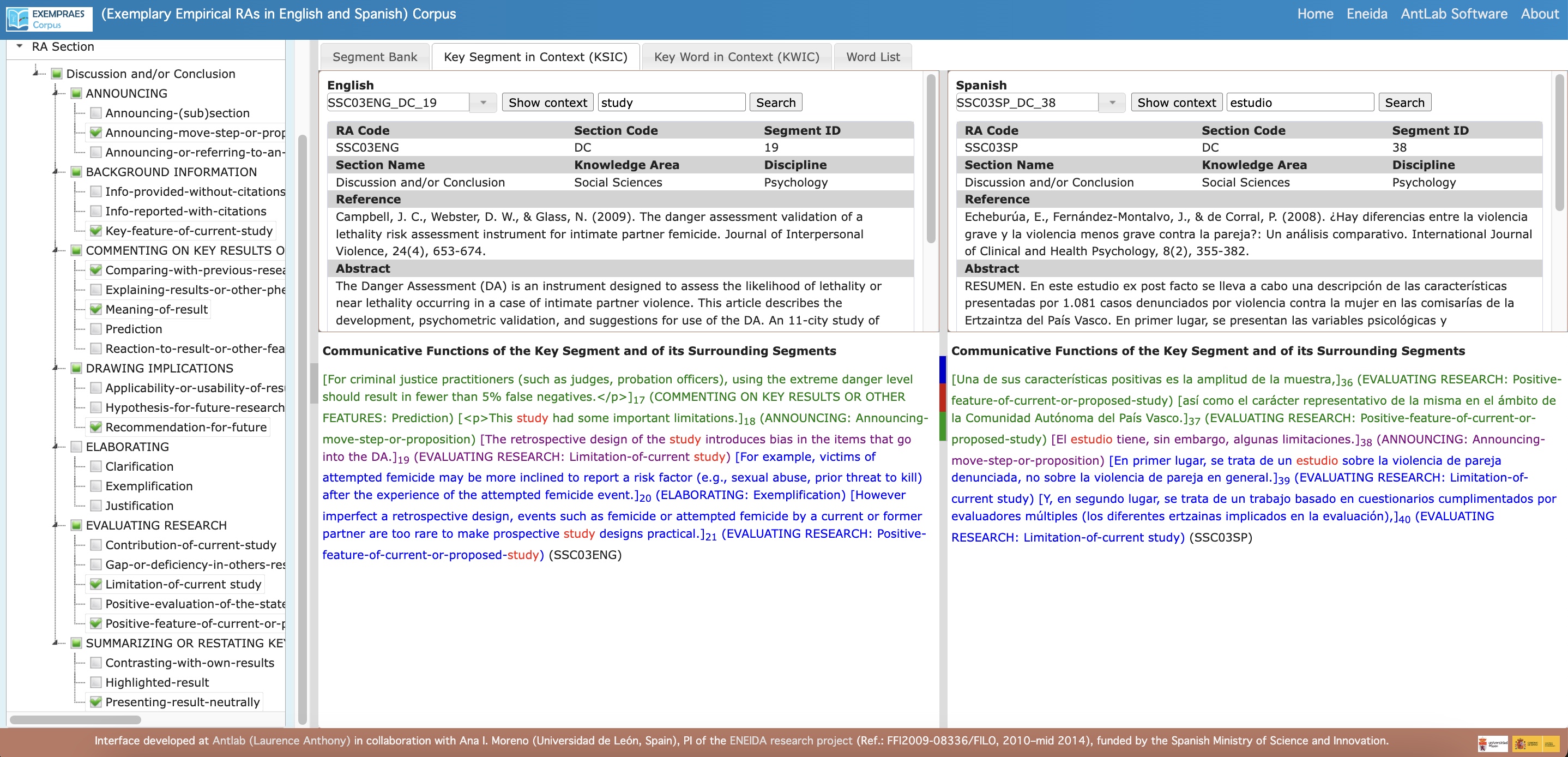
Conditions for the use of the EXEMPRAES Corpus
The EXEMPRAES Corpus is available for teaching and learning purposes under the following conditions:
- Source texts may not be reproduced in commercial teaching materials.
- Source texts may not be reproduced in full for a wider audience, but short passages (up to 250 words) may be cited.
If used for research purposes:
We kindly ask that the Principal Investigator (ana.moreno@unileon.es) be informed of any projects, dissertations, theses, presentations, or publications that result from the use of the corpus. We would love to learn about your research and its contributions to the field.
We are delighted to support academic research and greatly appreciate your acknowledgment of the corpus. To properly cite it, please include the following text in the acknowledgment section of any publications based on it:
"The data in this study come from the Exemplary Empirical Research Articles in English and Spanish (EXEMPRAES) Corpus, compiled and annotated by the ENEIDA Team for a research project (Ref.: FFI2009-08336/FILO, 2010–mid 2014) funded by the Spanish Ministry of Science and Innovation, with Ana I. Moreno as the PI."
Additionally, the interface should be cited as follows:
Moreno, A. I., & Anthony, L. (2024). EXEMPRAES Corpus [Software]. ENEIDA: Spanish Team for Intercultural Studies of Academic Discourse, Universidad de León. https://eneida.unileon.es/exempraes/corpus.
Until fully developed, access to the interface requires registration through: https://eneida.unileon.es/exempraescorpus.php.
For companies interested in using EXEMPRAES for commercial purposes, please contact ana.moreno@unileon.es to explore potential collaborations.
Participants and responsibilities
The Principal Investigator: Ana I. Moreno (ULE)
- Designing the essential features of the EXEMPRAES Corpus interface.
- Organising meetings with Laurence Anthony to communicate the ENEIDA team´s research and teaching needs.
- Revising the various interface versions.
- Testing UAM Corpus Tool for all aspects of the procedure from importing the texts in ‘.txt’ to exporting them with their annotations in ‘.xlsx’ format to be uploaded onto EXEMPRAES Corpus.
- Coordinating the import of annotated texts into the EXEMPRAES Corpus interface.
- Testing the corpus interface and offering feedback to the developer before launch.

The corpus interface developer: Laurence Anthony (Waseda University)

- Meeting with the Principal Investigator to understand the research and teaching needs.
- Developing and refining the EXEMPRAES Corpus interface based on indications and feedback from the Principal Investigator.
- Assisting in determining the best format for importing texts into and exporting them from UAM Corpus Tool.