Cross-cultural Studies > Methods and participants > Rhetorical structure analysis

ENEIDA Training in Rhetorical Structure Analysis
by John Swales
Segmenting Texts into Comparable Units
Given the aims of Phase 2, the cross-cultural studies focused their analyses on the research articles in the EXEMPRAES Comparable Corpora. This aspect of the methodology involved segmenting the various sections of these articles into smaller text units, or segments, that were comparable in communicative function. Before the detailed work began, John Swales conducted four workshops to ensure the ENEIDA Phase 2 team acquired common interpretation and analytical skills, regarding RA sections in English. However, we anticipated that cross-cultural comparison would bring about a number of challenges.
Challenges in Analysing Rhetorical Structure Cross-culturally
The primary challenges in analysing the rhetorical structure (RS) of the research articles (RAs) in the EXEMPRAES Comparable Corpora included:
- Analysing texts produced in different languages and knowledge areas into comparable smaller units to allow for detailed comparison at rhetorical levels across languages, knowledge areas, or RA sections.
- Ensuring all discourse analysts followed a consistent methodology for segmenting the various RA sections into cross-culturally meaningful text units, using common principles for labelling their communicative functions.
- Achieving reliable text segmentations and function assignments that could be replicated by other analysts.
- Segmenting and annotating the various research article sections in ways that provide useful results for target users and form the basis of future teaching ERPP materials.
Methodological Innovations and Decisions
To address these challenges, the following methodological framework was established:
- Common Methodological Framework: A uniform coding protocol was established for analysing and segmenting research article sections across different knowledge areas into smaller functional units.
- Section-Specific Analysis: Each co-investigator (coder) was tasked with analysing and segmenting a specific section of the research articles into functional units across all the knowledge areas represented in the sample corpora.
- Standardised Labelling: Each text unit was to be labelled with terms recognisable to the academic community involved in writing, reading or reviewing the various research article sections.
- Codebooks: The co-investigators were responsible for producing codebooks for coding their assigned sections to facilitate the replication of analysis.
- Independent Verification: At least one independent coder would analyse and segment a sample of each section according to the coding protocol and corresponding codebook.
- Reliability Testing: Reliability tests would be conducted on the results obtained by each co-investigator and an independent coder to validate the coding scheme and the coding.
Methods of Cross-cultural Rhetorical Structure Analysis
Analysing the rhetorical structure of the EXEMPRAES Corpora
The following steps were taken to analyse the rhetorical structure of the comparable research articles:

(Taken from Moreno, 2013)
The ENEIDA coding schemes
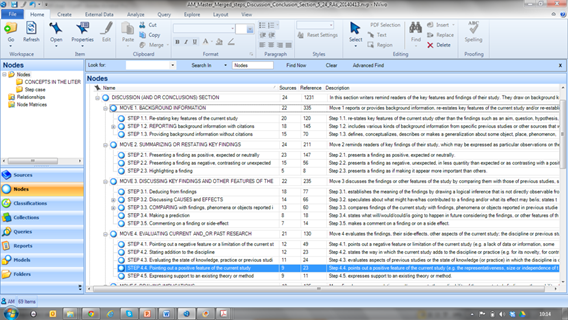
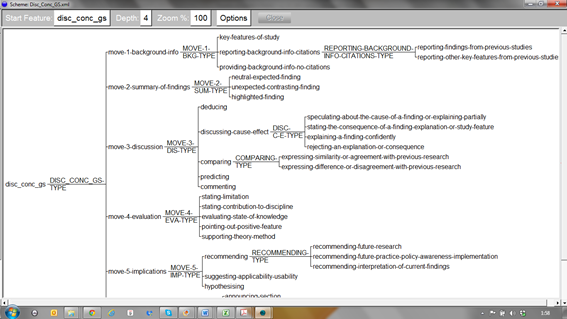
Each research article section gave rise to a distinct coding scheme of communicative functions, which included a limited number of moves and steps, as well as announcements and elaborations, within each section. This coding was performed using NVivo 10, a qualitative analysis software. The following graph shows a partial view of the preliminary coding scheme generated for the Discussion (and/or Conclusion) section.
(Taken from Moreno, 2014)
The central part of the screen shows the hierarchy of communicative functions identified, the number of sources containing each function and their absolute frequency. The right side includes a definition of each communicative function.
Process of comparable corpora annotation
- NVivo was employed for the initial qualitative aspects of the research, such as the coding schemes and inter-coder reliability tests. However, it was not suitable for quantitative studies as it handled only a small number of texts at a time.
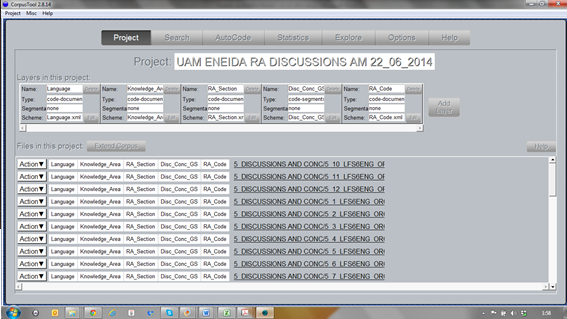
- The research articles in the EXEMPRAES Corpora (usually in .pdf format) were first converted into .txt format for handling by UAM Corpus Tool.
- UAM Corpus Tool was then used for annotating a sample of the EXEMPRAES Corpora in preparation for future quantitative studies.
- The research articles were divided into the following sections to facilitate handling by UAM Corpus Tool:
- 1. Title, authors, abstract(s) and keywords
- 2. Introduction (and Literature Review) sections
- 3. Methods sections
- 4. Results (and Discussion) sections
- 5. Discussion (and/or Conclusion) sections
Screenshot of the import of Discussion (and/or Conclusion) sections in UAM Corpus Tool
Screenshot of the preliminary coding scheme for Discussion (and/or Conclusion) sections in UAM Corpus Tool
- A common procedure for annotating the research article sections was followed by all ENEIDA annotators.
- Our annotations include mark-ups for relevant contextual variables (i.e. language, knowledge area, and section) and tags for all communicative functions (whether moves, steps, announcements or elaborations), according to the ENEIDA Coding schemes.
- To date, two matched sets of 12 exemplar research article Results (and Discussion) and Discussion (and/or Closing) sections from the EXEMPRAES Corpora have been annotated completely.